
Center for Problem-Oriented Policing
Step 22: Examine your data distributions
After collecting your data you need to know what it is telling you. Suppose you collected incidents of assaults on taxi drivers. Are assaults concentrated among a very few drivers? Are the assaults concentrated on some days of the week or times of day?
To answer these questions you need to look at the distribution of the data. The figure below displays the distribution of homicides across Cincinnati's 53 neighborhoods for a 36-month period. The horizontal axis shows the number of homicides in a neighborhood. The vertical axis shows how many neighborhoods had each of these numbers (so in the first column, 13 neighborhoods had zero homicides). Most neighborhoods had few homicides but there is a long tail stretching to the right where a few neighborhoods have many homicides.
Often you need to summarize a distribution. There are two basic descriptions of distributions: the typical, or average, case and the variation, or spread of cases.
The Average Case. The average can be calculated three ways:
- Mean. This is the most common measure of average. The mean number of homicides in the Cincinnati neighborhoods is 3.7 homicides per neighborhood - calculated by dividing the 198 killings by the 53 neighborhoods.
- Median. This is the value that divides the cases into two equal groups. Half the Cincinnati neighborhoods have two or more homicides and half have two or fewer.
- Mode. This is the value possessed by the greatest number of cases. In this example the mode is homicides because the biggest group of neighborhoods have no homicides.
The Spread of Cases. There are three common methods to measure spread:
- Range. This is most basic measure of spread. This is the lowest and highest value. In our example, the range is 0 to 27 homicides.
- Inner quartile range looks at the lower and upper bounds of the middle 50 percent of the cases. In the Cincinnati example, the inner quartile range is one to five homicides. Half the neighborhoods fall into this bracket. Another 25 percent of the neighborhoods have one or no homicides and the last 25 percent have 5 or more homicides. To find the inner quartile range, rank the cases and divide them into four equal groups. The two middle groups are the innerquartiles. The inner quartile range is the lowest and the highest value of these two middle groups.
- Standard deviation. This measure of spread indicates the mean difference from the mean of the distribution. The smaller the standard deviation, the smaller the average spread around the mean. The formula is rather tedious, but any spreadsheet or statistical software package can calculate it. Two thirds of the cases fall within one standard deviation on both sides of the mean. In the Cincinnati example, the standard deviation is 5.2 homicides.
FREQUENCY DISTRIBUTION OF HOMICIDES IN CINCINNATI NEIGHBORHOODS
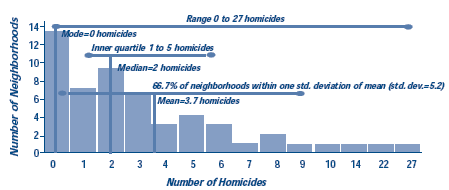
Which measures of typicality and spread are best depends on two characteristics of the data. The first is the symmetry of the distribution. In a symmetrical distribution, the shape on one side of the mean is mirrored on the other side. The mean equals the median in symmetrical distributions. If the value with the most cases is in the center, then the mode will be the same as the other two measures of average. But the mode need not equal the median or the mean. The distribution could have two modes, one on each side of the median. If the distribution is roughly symmetrical, the mean and standard deviation may be appropriate.
If the distribution is asymmetrical, then the mean and standard deviation should not be used. Use the median or the mode and the inner quartile or full range. In problem analysis, asymmetry is very common.
The second characteristic used to select measures of typicality and spread is the measurement scale used for the data. There are three common types of scales:
- Nominal scales simply apply labels. Gender (male=1, female=2) is measured with a nominal scale because the numbers simply substitute for word labels, and the categories could be relabeled, male=2, female=1 without creating a problem. If your data is nominal, then only a mode is appropriate.
- Ordinal scales rank cases as well as label them. An ordered list of neighborhoods, from greatest to fewest homicides produces an ordinal scale (first, second, third, through fifty-third). You cannot add and subtract, multiply and divide ordinal data. You can only determine if a case has a greater, lesser or equal rank to another case. If the data is ordinal, neither the mean nor the standard deviation can be used. Use the median and inner quartile range.
- Ratio scales allow you to add, subtract, multiply and divide because the difference between each value is equal and there is a meaningful zero. The number of homicides in a neighborhood is measured with a ratio scale: the difference between 0 homicides and 1 homicide is the same as the difference between 26 homicides and 27 homicides, and 0 homicides has meaning. You can use a mean and standard deviation with this type of data.
TYPES OF DATA, THEIR USE, AND THEIR LIMITATIONS
| Nominal | Ordinal | Ratio | |
|---|---|---|---|
| Description | Names categories | Ranks & names categories | Has equal intervals between numbers, and zero is meaningful. |
| Example | 0= not victim 1= victim is as valid as 0= victim 1= not victim | 0= no crime 1= one crime 2= more than one crime | Number of crimes: 0, 1, 2,... (0= no crimes) |
| Scales to the right have all the properties of those to their left, plus their own properties (e.g., anything you can do with nominal and ordinal data you can do with ratio data, plus more). | |||
| Allowable Math | Same or not same | Greater, lesser, or equal | Addition, subtraction, multiplication, & division |
| Allowable Average | Mode | Median & Mode | Mean, Median, & Mode |
| Allowable Spread | Range | Inner quartile range & Range | Standard deviation & others |
| Comments | Used when dealing with categories (e.g., gender) and groups (e.g. chain stores, not chain stores). | Use when there is a natural ranking or order to categories (e.g., police ranks) but the differences between ranks is not always the same or unclear. | Use for percents, counts, and a host of other measures. |